Content:
- Understanding Kafka’s Architecture
- Multi-threaded Applications with Kafka
2.1. Parallel Processing
2.2. Scalability and Elasticity
2.3. Fault Tolerance and Reliability
2.4. Real-Time Data Streaming - When to use Kafka for Applications
3.1. Specific architecture
3.2. Application type
3.3. Context - Conclusion
1. Understanding Kafka’s Architecture
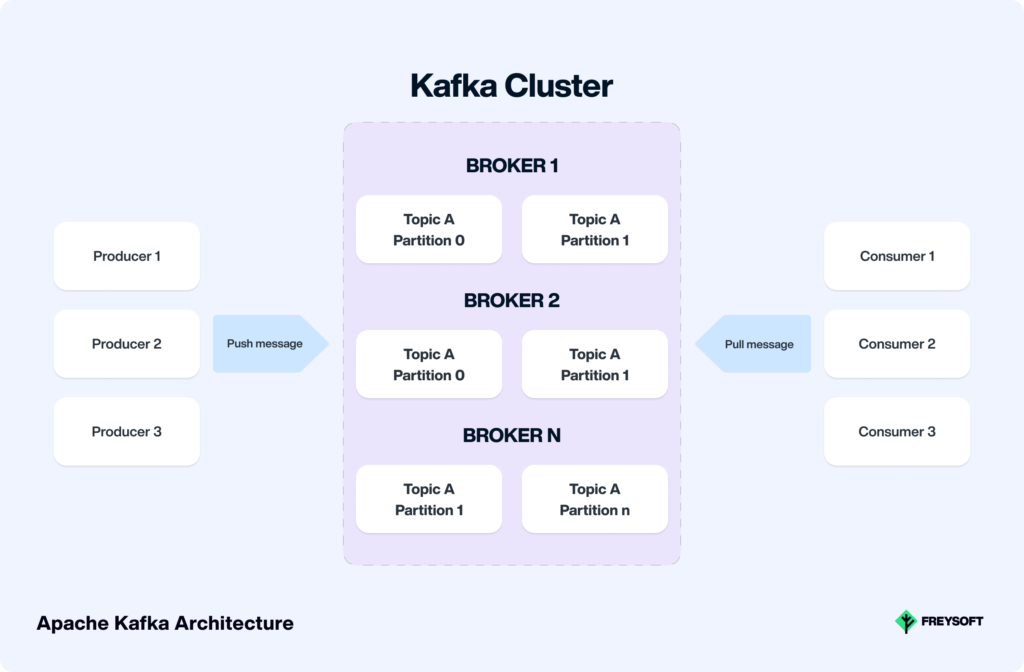
Simply put, Kafka is a system that helps messages go from one place to another, even if something goes wrong. It has different parts that work together to make sure messages are sent and received reliably. Here are the main components:
- Producers
Producers generate data or messages and publish them to Kafka topics. These messages can be produced in any programming language or framework, and this makes it easy to integrate with various application components. - Topics and Partitions
Kafka puts messages into groups called ‘topics.’ Each topic is made up of smaller parts called ‘partitions.’ This way, lots of messages can be managed together. - Brokers
Basically, brokers are the Kafka servers. They form the cluster and store the messages in partitions. Besides, they handle the data replication and distribution across the cluster. They keep the messages safe and organized in partitions. They also make sure copies of messages are saved, so nothing gets lost even if something breaks. - Consumers
Consumers subscribe to specific topics and read messages from the partitions. In a nutshell, they process the data in real time. Besides, they can be scaled horizontally by adding more consumer instances to handle increased workloads.
You can see the architecture of Kafka cluster and its workflow below.
You might also be interested in:
Our custom software blog
“Apple Sign In With Keycloak: How To Setup With Ease”
“SaaS Software Development: process, challenges & benefits”
“Payment Orchestration Platform: How It Works and Why So Important”
2. Kafka and Multi-threaded Applications
Before we dive deep into when to use Kafka, let’s explore the practical aspects of how Kafka benefits multi-threaded applications.
2.1. Parallel Processing
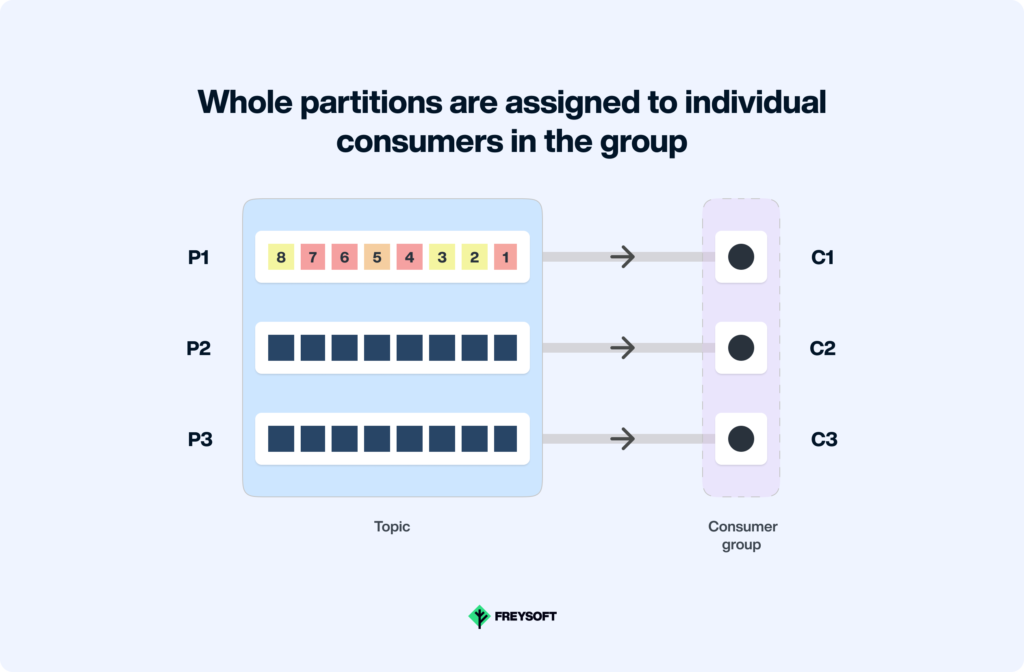
Kafka is set up in parts, and this lets lots of worker threads read from different parts at the same time. This means messages can be worked on together. Using many threads at once makes the best use of the computer’s power and makes things faster. Also, if you need to handle even more data, you can just add more worker threads and do even more at once.
For example, let’s look at a large e-commerce company like Amazon. How can this company benefit from Kafka? They may use Kafka to process high volumes of customer transactions in real time. Basically, each transaction is a message that is processed by a consumer thread. With Kafka’s partitioned design, multiple consumer threads can process different transactions concurrently. Obviously this feature allows the company like Amazon to handle peak shopping periods efficiently.
2.2. Scalability and Elasticity
Kafka’s setup lets you easily expand both producers and consumers. Moreover, when you have more data to handle, you can add more consumer threads to spread out the work and keep things speedy. If you’re making more data, you can get more producers to handle the load. This makes Kafka great for tasks that have changing amounts of work.
For example, look at how Twitter uses Kafka. They handle tons of tweets, retweets, and likes coming in every second. And as the number of these events goes up, Twitter just adds more consumer threads to spread the load and keep everything moving quickly.
2.3. Fault Tolerance and Reliability
Kafka is built so that if something goes wrong, your data is still safe. It spreads your data out over many brokers. So, even if one breaks, your data is still there. If a consumer has a problem, Kafka can fix it by moving the work around. This way, your programs stay reliable even if things mess up.
Netflix relies on Kafka for keeping an eye on its systems in real time. If something goes wrong, the data’s still there, spread out over many brokers. This means Netflix can keep checking its systems and quickly notice any problems, even when things break.
2.4. Real-Time Data Streaming
Kafka is perfect when you need to handle a lot of data really quickly. It’s great for processing things as they happen, looking at live data, or setting up systems that react to events. With Kafka, your programs can get and send data almost immediately.
Uber uses Kafka to track its drivers and riders in real time. This helps Uber match up drivers and riders quickly and keeps an accurate eye on where they are.
3. When to Use Kafka for Applications
LinkedIn, the company that initially developed Kafka, uses it to track user activity data and operational metrics. This data is then used for real-time monitoring, analysis, and anomaly detection. For example, LinkedIn’s architecture involves continuous streams of data that are generated and processed in real time. In fact, it makes LinkedIn a perfect fit for Kafka.
Obviously, purchasing a single car doesn’t mean you can travel in any direction. You also need roads and infrastructure to reach your destination. The same goes for Kafka — it’s a powerful tool. Still, for successful use in multi-threaded applications, you need the right architecture, application type, context, and a well-designed data processing system.
3.1. Architecture
Kafka is particularly suitable for real-time streaming data processing systems.
In this architecture, the data producers generate continuous streams of data, which are then ingested by Kafka producers. Kafka acts as a distributed messaging system that decouples the data producers from the data consumers. The data consumers, also known as Kafka consumers, process and analyze the data in real time. They can be implemented as separate microservices or components within a larger application.
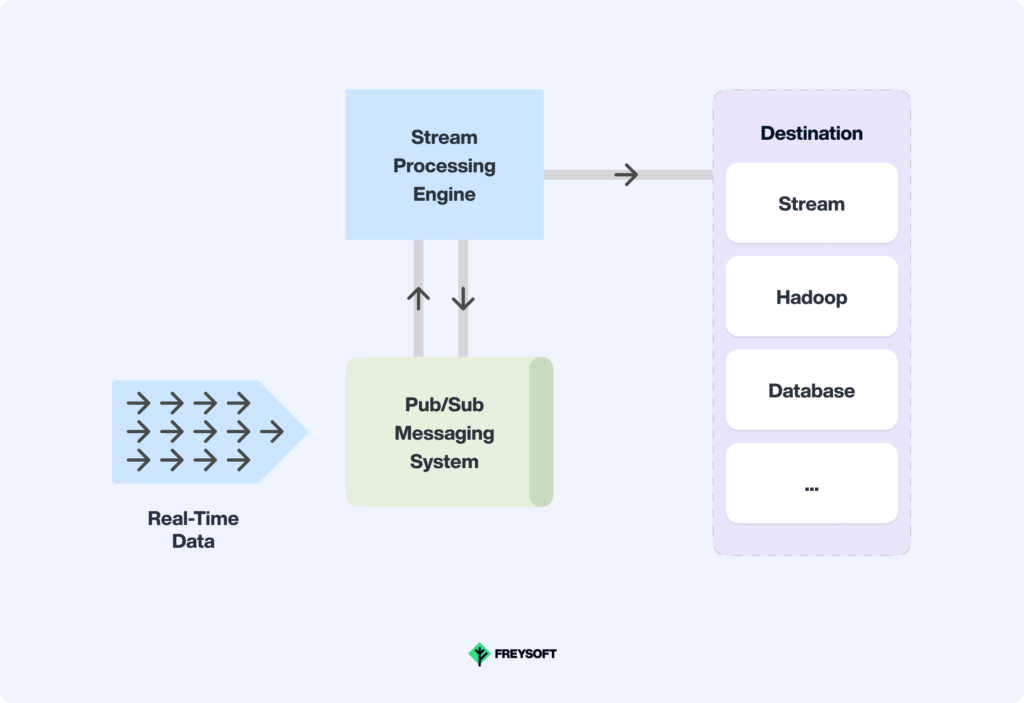
3.2. Application Type
Real-time streaming data processing applications are commonly used in various domains, such as:
- Internet of Things (IoT)
Devices generate a massive amount of data that needs to be processed and analyzed in real-time, for applications like sensor data monitoring, anomaly detection, or predictive maintenance. - Financial Services
Applications that involve real-time transaction processing, fraud detection, or real-time risk analysis benefit from the ability to ingest and process high-volume data streams in real time. - Social Media and Advertising
Platforms that handle large-scale user-generated content, perform real-time sentiment analysis, or deliver personalized advertisements can leverage Kafka to handle the continuous streams of data and enable real-time processing.
3.3. Context
Multi-threaded applications with Kafka shine best in scenarios that require handling high-throughput, fault-tolerant, and scalable data streams. Kafka provides built-in features like replication, fault tolerance, and automatic load balancing. These features ensure data reliability and scalability. It also supports parallel processing and enables data streaming between different components or microservices of the application.

With Kafka’s publish-subscribe model and the ability to store data for a configurable period, it allows data consumers to process the data at their own pace, replay past events, or perform batch processing if needed.
4. Conclusion
Multi-threaded applications with Kafka open up a world of possibilities for building highly scalable, fault-tolerant, and real-time data processing systems. Its parallel processing capabilities, scalability, fault tolerance, and real-time data streaming make it an excellent choice for applications that demand efficient handling of vast amounts of data.
However, our recommendation is to remember that Kafka may not be the best solution for all situations. There are many other message-queuing systems that can also be useful for multi-threaded applications. Choosing the right tool should be based on your specific situation, needs, and project constraints.
It’s important to assess your requirements and consider factors such as scalability, reliability, performance, and integration capabilities when evaluating Kafka or alternative messaging systems. Each system has its strengths and weaknesses, so it’s crucial to make an informed decision based on your unique circumstances.
You might also read:
Modernize your IT systems without breaking them
Cloud Migration: Five-Steps Approach to Your Successful Process
Interview with two FreySoft DevOps engineers